1. 분류 분석과 예측 분석
1) 개요
| 공통점 | 레코드의 특정 속성의 값을 미리 알아 맞히는 것 |
| 차이점 | 분류는 레코드의 범주형 속성의 값을 알아 맞히는 것 예측은 레코드의 연속형 속성의 값을 알아 맞히는 것 |
| 분류의 예 | 학생들의 국어, 영어 등 점수를 통해 내신등급을 예측 카드회사에서 회원들의 가입정보를 통해 1년 후 신용등급을 예측 |
| 예측의 예 | 학생들의 여러 가지 정보를 입력해 수능점수를 예측 카드회사에서 회원들의 가입정보를 통해 연 매출액을 예측 |
| 분류 모델링 | 신용평가모형, 사기방지모형, 이탈모형, 고객세분화 |
| 분류 기법 | 로지스틱 회귀분석 의사결정나무, CART, C5.0 베이지안 분류 인공신경망 지지도벡터기계 k 최근접 이웃 규칙기반의 분류와 사례기반 추론 |

2. 의사결정 나무
1) 정의와 특징
- 분류 함수를 의사결정 규칙으로 이뤄진 나무 모양으로 그리는 방법으로, 의사결정 문제를 시각화해 의사결정이 이뤄지는 시점과 성과를 한눈에 볼 수 있게 함
- 주어진 입력값에 대해 출력 값을 예측하는 모형으로 분류 나무와 회귀 나무 모형이 있음

- 특징
* 계산 결과가 의사결정 나무에 직접 나타나게 돼 분석이 간편함
* 분류 정확도가 좋음
* 계산이 복잡하지 않아 대용량 데이터에서도 빠르게 만들 수 있음
* 비정상 잡음 데이터에 대해서도 민감함 없이 분류
* 한 변수와 상관성이 높은 다른 불필요한 변수가 있어도 크게 영향받지 않음
2) 활용
| 세분화 | 데이터를 비슷한 특성을 갖는 몇 개의 그룹으로 분할해 그룹별 특성을 발견 |
| 분류 | 관측개체를 여러 예측변수들에 근거해 목표변수의 범주를 몇 개의 등급으로 분류하고자 하는 경우 |
| 예측 | 자료에서 규칙을 찾아내고 이를 이용해 미래의 사건을 예측하고자 하는 경우 |
| 차원축소 및 변수선택 | 매우 많은 수의 예측변수 중 목표변수에 영향을 미치는 변수들을 골라내고자 하는 경우 |
| 교호작용효과의 파악 | 여러 개의 예측변수들을 결합해 목표 변수에 작용하여 파악하고자 하는 경우 |
| 범주의 병합 또는 연속형 변수의 이산화 | 범주형 목표변수의 범주를 소수의 몇 개로 병합하거나 연속형 목표변수를 몇 개의 등급으로 이산화 하고자 하는 경우 |
3) 의사결정 나무의 분석 과정
- 분석 단계 : 성장 -> 가지치기 -> 타당성 평가 -> 해석 및 예측
- 가지치기 : 너무 큰 나무 모형은 자료를 과대 적합하고 너무 작은 나무 모형은 과소 적합할 위험이 있어 마디에 속한 자료가 일정 수 이하일 경우, 분할을 정지하고 가지치기 실시
- 불순도에 따른 분할 측도 : 카이제곱 통계량, 지니 지수, 엔트로피 지수
4) 의사결정 나무 분석의 종류
| CART | - 목적변수가 범주형인 경우 지니지수, 연속형인 경우 분산을 이용해 이진분리를 사용 - 개별 입력변수 뿐만 아니라 입력변수들의 선형결합들 중 최적의 분리를 찾을 수 있음 |
| C4.5와 C5.0 | - 다지분리가 가능하고 범주형 입력 변수와 범주 수만큼 분리 가능 - 불순도의 측도로 엔트로피 지수 사용 |
| CHAID | - 가지치기를 하지 않고 적당한 크기에서 나무모형의 성장을 중지하며 입력변수가 반듯이 범주형 변수여야 함 - 불순도의 측도로 카이제곱 통계량 사용 |
3. 앙상블 기법
1) 개요
- 주어진 자료로부터 여러 개의 예측모형들을 만든 후 조합하여 하나의 최종 예측모형을 만드는 방법
- 다중 모델 조합, classifier combination 방법이 있음
- 학습 방법의 불안전성을 해결하기 위해 고안된 기법
- 가장 불안정성을 가지는 기법은 의사결정 나무, 가장 안정성을 가지는 기법은 1-nearest neighbor
2) 기법의 종류
| 배깅 | - 여러 개의 붓스트랩 자료를 생성하고 각 붓스트랩 자료의 예측모형 결과를 결합하여 결과를 선정 - 배깅은 훈련자료를 모집단으로 생각하고 평균 예측모형을 구한 것과 같이 분산을 줄이고 예측력을 향상 시킬 수 있음 |
| 부스팅 | - 예측력이 약한 모형들을 결합하여 강한 예측모형을 만드는 방법 훈련오차를 빨리 그리고 쉽게 줄일 수 있고, 예측오차의 향상으로 배깅에 비해 뛰어난 얘측력을 보임 |
| 랜덤 포레스트 | - 의사결정나무의 특징인 분산이 크다는 점을 고려하여 배깅과 부스팅보다 더 많은 무작위성을 주어 약한 학습기들을 생성한 후 이를 선형 결합하여 최종 학습기를 만드는 방법 - 이론적 설명이나 해석이 어렵다는 단점이 있지만 예측력이 매우 높은 장점이 있음 입력변수가 많은 경우 더 좋은 예측력을 보임 |

4. 성과분석
1) 오 분류표를 통한 모델 평가
2) ROC
- 민감도와 1-특이도를 활용하여 모형을 평가
- AUROC(ROC 커브 밑부분의 넓이) - AUROC = (AR+1)/2
| AUROC | 등급 |
| 0.9 ~ 1.0 | Excellent |
| 0.8 ~ 0.9 | Good |
| 0.7 ~ 0.8 | Fair |
5. 인공신경망
1) 신경망의 연구
- 인공신경망은 뇌를 기반으로 한 추론 모델
- 1943년 매컬럭과 피츠 : 인간의 뇌를 수많은 신경세포가 연결돼 하나의 디지털 네트워크 모형으로 간주하고 신경세포의 신호처리 과정을 모형화하여 단순 패턴 분류 모형을 개발
- 햅 : 신경세포(뉴런) 사이의 역녈강도를 조정하여 학습 규칙을 개발
- 로젠 블럿 : 퍼셉트론이라는 인공세포 개발, 비선형성의 한계점 발생 - XOR 문제
- 홉 필드, 러멜 하트, 맥클랜드 : 역전파 알고리즘을 활용하여 비선형성을 극복한 다계층 퍼셉트론으로 새로운 인공신경망 모형 등장

2) 뉴런
- 인공신경망은 뉴런이라는 아주 단순하지만 복잡하게 연결된 프로세스로 이루어져 있음
- 뉴런은 가중치가 있는 링크들로 연결되어있으며, 뉴런은 여러 개의 입력 신호를 받아 하나의 출력 신호를 생성
- 뉴런은 전이 함수, 즉 활성화 함수를 사용
*뉴런은 입력 신호의 가중치 합을 계산하여 임계값과 비교
*가중치 합이 임계값보다 작으면 뉴런의 출력은 -1, 같거나 크면 +1을 출력함

3) 신경망 모형 구축 시 고려사항
| 입력변수 | - 신경망 모형은 복잡성으로 인해 입력자료의 선택에 매우 민감 - 범주형 변수(각 범주의 빈도가 일정수준 이상이고 각 범주의 빈도가 일정할 때 활용) ex) 가변수화하여 적용 (성별[남,녀] -> 남성[1,0], 여성[1,0] - 연속형 변수 (입력 값의 범위가 변수들간에 큰 차이가 없을 때 활용, 분포가 대칭이 아니면 좋지 않은 결과 도출, 변환 또는 범주화 활용) |
| 가중치 초기값 | - 역전파 알고리즘의 경우, 초기값에 따라 결과가 많이 달라져 초기값 선택이 매우 중요 - 가중치가 0이면 시그모이드 함수는 선형이 되고 신경망 모형도 선형모형이 됨 - 초기값은 0 근처의 랜덤 값으로 선정하고 초기에는 선형모형에서 가중치가 증가하면서 비선형으로 변경됨 |
| 예측값 선정 | - 비용함수 R는 비볼록함수이고 여러 개의 국소 최소값들을 가짐 - 랜덤하게 선택된 여러 개의 초기값에 대한 신경망을 적합한 후 얻응 해들을 비교하여 가장 오차가 작은 것을 선택하여 최종 예측값을 얻거나 평균(또는 최빈값)을 구하여 최종 예측값으로 선정 - 훈련자료에 대하여 배깅을 적용하여 최종 예측치를 선정 |
| 학습률 | - 상수값을 사용하며, 처음에는 큰 값으로 정하고 반복이 진행되어 해가 가까울 수록 0에 수렴 |
| 은닉층, 은닉 노드의 수 | - 은닉층과 은닉노드가 많으면 - 가중치가 많아져서 과대 적합 문제 발생 - 은닉층과 은닉노드가 적으면 - 과소 적합 문제 발생 - 은닉층 수 결정 : 은닉층이 하나인 신경망은 범용근사자이므로 가급적이면 하나로 선정 - 은닉노드 수 결정 : 적절히 큰 값으로 결정하고 가중치를 감소하면서 모수에 대한 벌점화 적용 |
| 과대 적합 문제 | - 신경망은 많은 가중치를 추정해야 하므로 과대적합 문제가 빈번 - 해결방법 : 조기종료(모형이 적합하는 과정에서 검증오차가 증가하기 시작하면 반복을 중지 선형모형의 능형회귀와 유사한 가중치 감소라는 벌점화 기법 활용 |

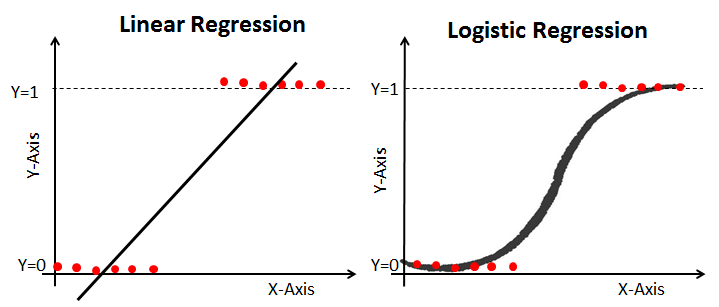
6. 로지스틱 회귀분석
1) 개요
- 반응 변수가 범주형인 경우에 적용되는 회귀분석모형
- 새로운 설명변수(또는 예측 변수)가 주어질 때 반응 변수의 각 범주(또는 집단)에 속할 확률이 얼마인지를 추정(예측모형)하여, 추정 확률을 기준치에 따라 분류하는 목적(분류 모형)으로 활용
- 이때 모형의 적합을 통해 추정된 확률을 사후 확률이라고 함
- exp의 의미는 나머지 변수가 주어질 때, x1이 한 단위 증가할 때마다 성공의 오즈가 몇 배 증가하는지를 나태는 값
- glm() 함수를 활용하여 로지스틱 회귀분석을 실행함
'데이터분석' 카테고리의 다른 글
| 데이터의 이해 (0) | 2021.11.16 |
|---|---|
| 연관분석 (0) | 2021.11.15 |
| 군집분석 (0) | 2021.11.13 |
| 데이터 마이닝 개요 (0) | 2021.11.12 |
| 다차원 척도법과 주성분분석 (0) | 2021.11.11 |



