1. 연관분석
1) 개요
- 기업의 데이터베이스에서 상품의 구매, 서비스 등 일련의 거래 또는 사건들 간의 규칙을 발견하기 위한 분석 흔히 장바구니 분석, 순차 분석 등이 있음
- 장바구니 분석 : 장바구니에 무엇이 같이 들어 있는지에 대해 분석
ex) 주말을 위해 목요일에 기저귀를 사러 온 30대 직장인 고객은 맥주도 함께 사감
- 순차분석 : 구매 이력을 분석해서 A 품목을 산 후 B 품목을 사는지를 분석
ex) 휴대폰을 새로 구매한 고객은 한 달 내에 휴대폰 케이스를 구매

2) 형태
- 조건과 반응의 형태(if-then)
3) 측도
| 지지도 | 전체 거래 중 항목 A오 항목 B를 동시에 포함하는 거래의 비율로 정의 |
| 신뢰도 | 항목 A를 포함한 거래 중에서 항목 A와 항목 B가 같이 포함될 확률, 연관성의 정도를 파악할 수 있음 |
| 향상도 | A가 주어지지 않았을 때의 품목 B의 확률에 비해 A가 주어졌을 때의 품목 B의 확률의 증가 비율 연관규칙 A->B는 품목 A와 품목 B의 구매가 서로 관련이 없는 경우에 향상도가 1이 됨 |
4) 특징
- 절차
1) 최소 지지도 선정 (보통 5%)
2) 최소 지지도를 넘는 품목 분류
3) 2가지 품목 집합 생성
4) 반복 수행으로 빈발품목 집합 선정
- 장점과 단점
| 장점 | 단점 |
| 탐색적인 기법 - 조건 반응으로 표현되는 연관성분석 결과를 쉽게 이해할 수 있음 |
상당한 수의 계산과정 - 품목 수가 증가하면 분석에 필요한 계산은 기하급수적으로 늘어남 |
| 강력한 비목적성 분석기법 - 분석 방향이나 목적이 특별이 없는 경우 목적변수가 없으므로 유용하게 활용됨 |
적절한 품목의 결정 - 너무 세분화한 품목을 갖고 역관성 규칙을 찾으면 수많은 연관성 규칙들이 발견되겠지만, 실제로 발생 비율 면에서 의미 없는 분석이 될 수도 있음 |
| 사용이 편리한 데이터의 형태 - 거래 내용에 대한 데이터를 변환 없이 그 자체로 이용 |
품목의 비율차이 - 사용될 모든 품목들 자체가 전체자료에서 동일한 빈도를 갖는 경우, 연관성 분석은 가장 좋은 결과를 얻음. 그러나 거래량이 적은 품목은 당연히 포함된 거래수가 적을 것이고 규칙 발견 과정 중에서 제외되기 쉬움 |
| 계산의 용이성 - 분석을 위한 계산이 상당히 간단 |
5) 평가기준 적용시 주의점
- 두 항목의 신뢰도가 높다고 해서 꼭 두항 목이 높은 연관관계가 있는 것은 아님 (지지도를 함께 고려)
* 만일 두 항목의 신뢰도가 높게 나왔어도 전체 항목 중 두 항목의 동시 구매율인 지지도가 낮게 나온다면 두 항목 간 연관성을 신뢰하기에는 부족한 점이 있음
* 즉, 구매율 자체가 낮은 항목이기에 일반적인 상관관계로 보기엔 어려움
- 지지도와 신뢰도가 모두 높게 나왔더라도 꼭 두 항목이 높은 연관관계가 있는 것은 아님 (향상도를 함께 고려)
* 일반적으로 빈번하게 구매되는 항목들에 대해서는 지지도와 신뢰도가 높게 나올 수 있음
- A,B 두 항목의 신뢰도가 높게 나왔을 때, 전체 거래에서 B의 자체 구매율보다 A자체 구매율이 더 높아야 의미 있는 정보임
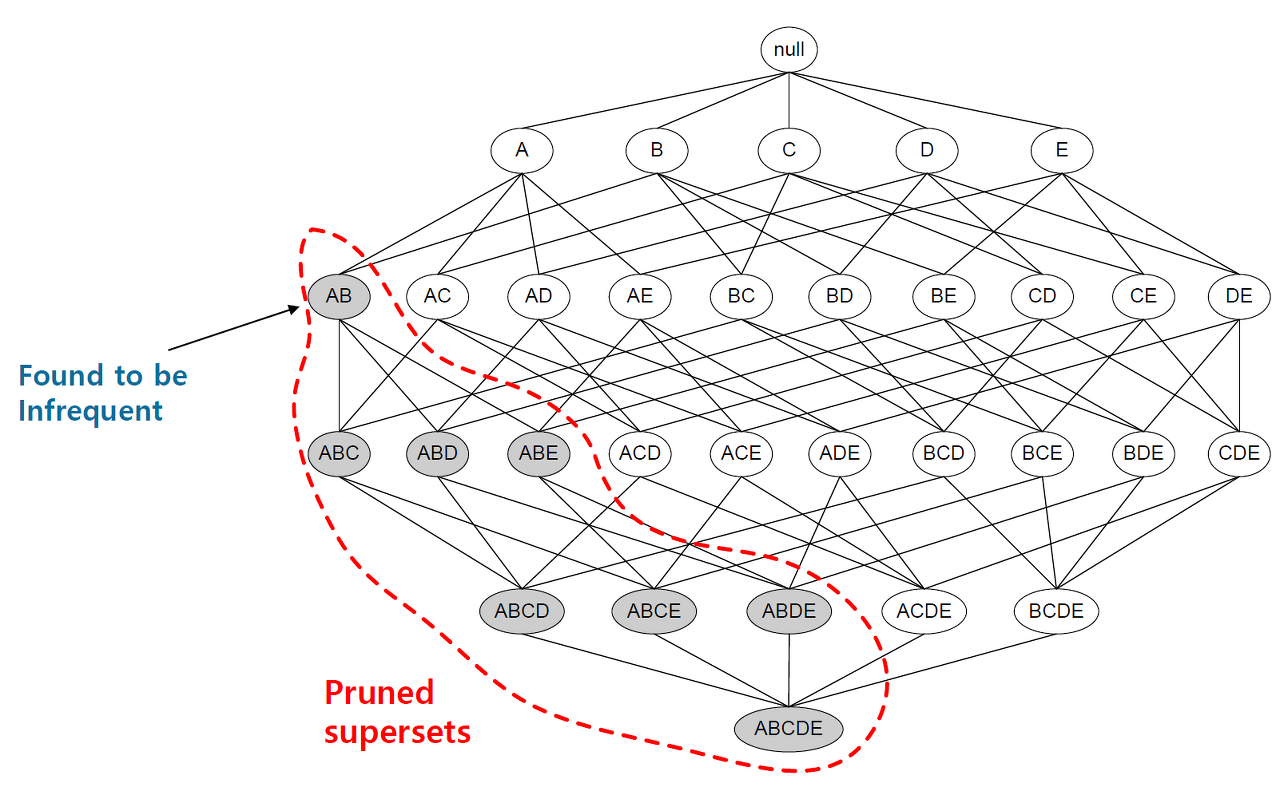
6) Apriori 알고리즘
- 어떤 항목집합이 빈발하다면, 그 항목 집합의 모든 부분집합도 빈발
ex) {우유, 빵, 과자}가 빈발 항목집합이면, 부분집합인 {우유, 빵}{우유, 과자}{빵, 과자}도 빈발 항목 집합 지지도의 anti-monotone 성질 : 어떤 항목 집합의 지지도는 그 부분집합들의 지지도를 넘을 수 없음.